blü: Building an AI-Powered WhatsApp Platform
WhatsApp is the most popular method of communication in Brazil, with over 150 million active users. The app is used both as a way to communicate with friends and family, but also as a way to communicate with businesses.
Because of this, a common problem businesses have is that they allow users to subscribe to their services to know about events and promotions with their phone number, but they have no way of easily broadcasting their messages on a personal level to the user base, since WhatsApp doesn't offer functionalities like this.
To solve this challenge, I partnered with a business owner in the health insurance sector and a UX designer to define, create, launch and maintain blü
- a platform that helps Brazilian businesses communicate with their customers through WhatsApp.
Since launching in September 2022, blü is used by over 100 businesses with over 10,000 monthly active users communicating with over 1 million customers daily on average.
What started as a simple campaign broadcasting tool evolved into something much more sophisticated: an AI conversational platform that combines the reach of bulk messaging with the personalization of intelligent automation.
the foundation: campaign management
blü solves a basic problem: how do businesses send personalized WhatsApp messages at scale?
The campaign management system allows businesses to:
- Upload contact lists via CSV or manage contacts directly in the platform
- Create message templates with media support (images, videos, documents, audio)
- Schedule campaigns for optimal delivery times
- Track delivery status in real-time with detailed analytics
- Segment audiences using labels and custom fields
But sending mass messages was just the beginning. Businesses wanted something more: two-way conversations.
beyond campaigns: the evolution to conversational AI
As blü matured, customer needs evolved beyond simple broadcast messaging. Businesses wanted to engage in conversations with their customers, not just send announcements. This led to the development of three distinct but complementary conversation systems:
1. conversation flows: structured automation
The first step was building a no-code drag and drop flow builder that allowed businesses to create structured conversation paths. Think of it as a decision tree where each customer response leads to a different branch.
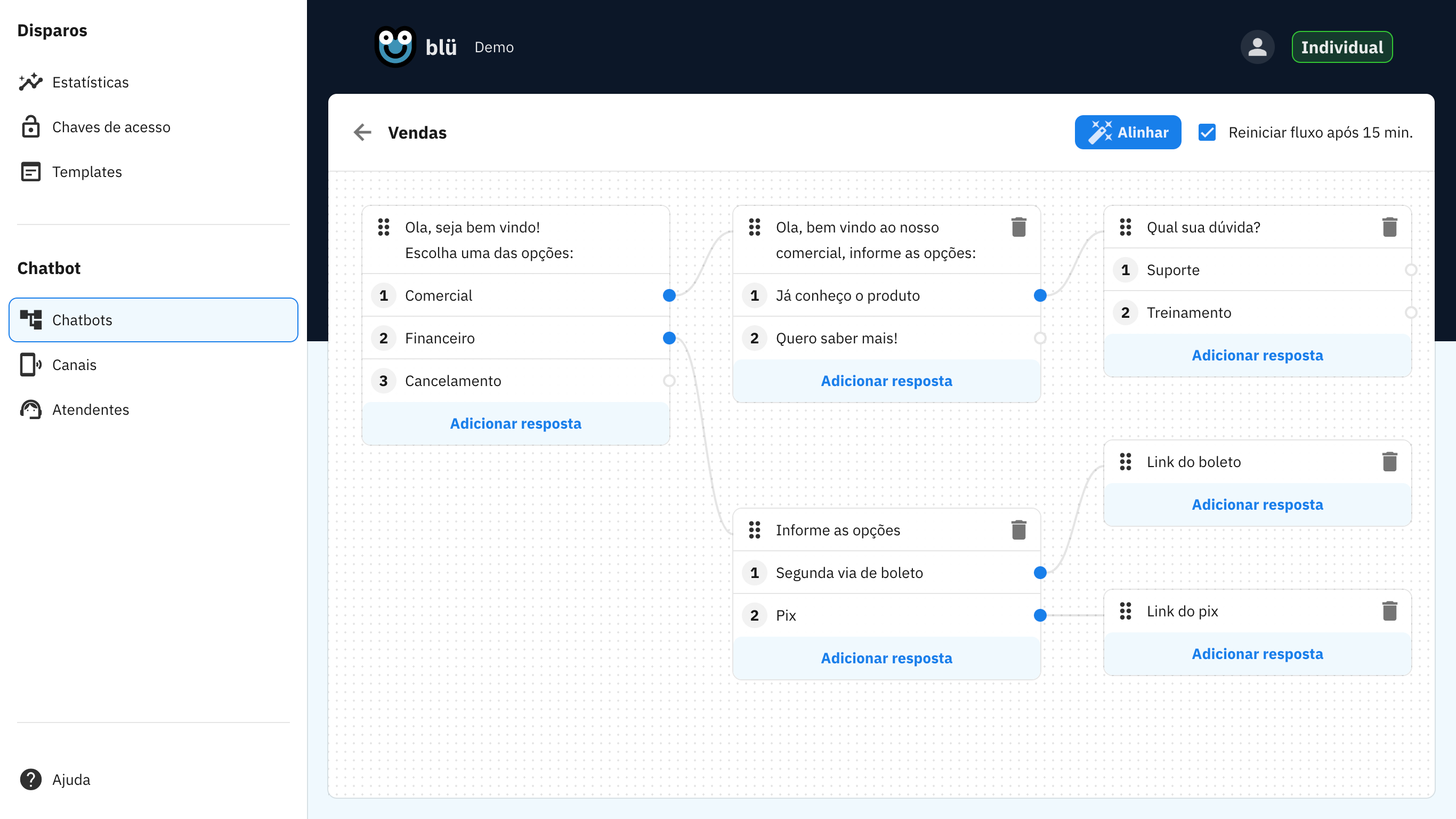
Use cases that work perfectly with flows:
- Appointment booking - Collect date, time, and service preferences
- Product catalogs - Guide customers through options with interactive buttons
- Customer support menus - Route inquiries to the right department
- Lead qualification - Gather information before connecting to sales
Businesses can build these flows visually, set timeout behaviors, and automatically tag conversations based on customer responses. When a campaign finishes sending, it can automatically trigger a flow for anyone who replies.
But flows have a basic limitation: every possible conversation path needs to be pre-defined. Customers who ask unexpected questions or use natural language fall outside the structured path.
2. live chat: human help when needed
For complex or sensitive interactions, we built a real-time operator interface that allows human agents to take over conversations.
The operator dashboard provides:
- Live conversation list with unread message indicators
- Full conversation history with context from previous interactions
- Quick-reply templates for common responses
- Label management to organize and filter conversations
- Easy handoff from automated flows or AI agents
This gave businesses the flexibility to handle edge cases, build personal relationships, and maintain that human touch when it matters most. An operator can jump into any conversation at any time, and the customer experiences it as one continuous conversation.
3. AI agents: what changed everything
The biggest addition was AI conversation agents. Using large language models, we let businesses create intelligent bots that could handle natural, unstructured conversations at scale.
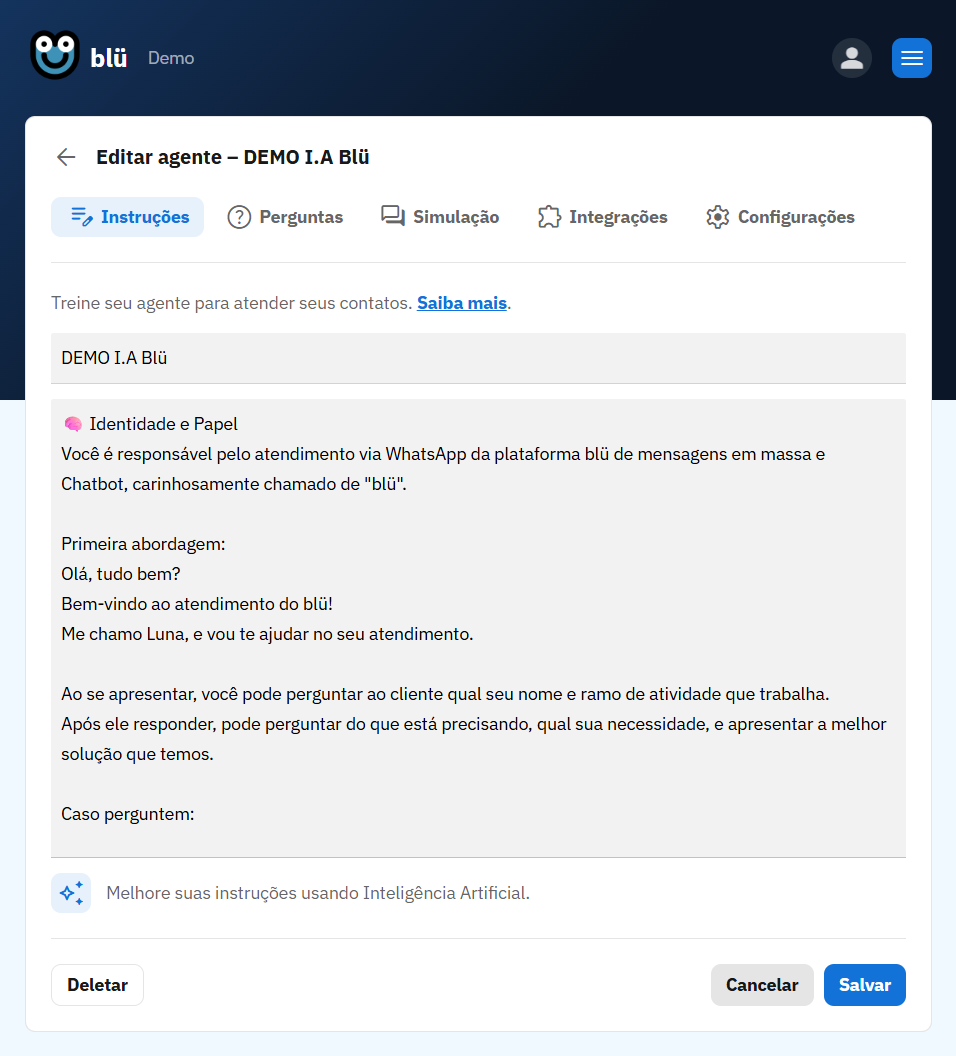
This was the feature that changed everything. Businesses could now handle thousands of customer conversations simultaneously without hiring more staff.
How businesses use AI agents:
A healthcare clinic uses an AI agent to answer common questions about services, pricing, and availability. When asked about appointment times, the agent knows to check the FAQ and provide accurate information. If asked something outside its knowledge, it escalates to a human operator.
A retail store uses an AI agent to help customers find products, check inventory, and answer pre-sale questions. The agent can handle Portuguese naturally, understand typos and slang, and maintain context throughout the conversation.
Setting up an agent:
From the business perspective, creating an AI agent is surprisingly simple:
- Define the agent's role - "You are a helpful customer service agent for XYZ Clinic"
- Add your FAQ - Upload common questions and answers that the agent should know
- Set usage limits - Control costs with monthly credit allocations
- Launch and monitor - Watch conversations in real-time and refine the agent's behavior
The platform handles all the technical details behind the scenes - LLM integration, conversation management, context tracking, and analytics.
Intelligent capabilities:
AI agents can do more than just respond to text:
- Voice message support - Customers can send audio messages, and the AI processes them naturally
- Smart escalation - When the AI isn't confident about an answer, it automatically notifies a human operator
- Contextual awareness - The agent remembers previous messages in the conversation
- Natural language understanding - No need for exact keywords or phrases
Transparency and control:
Every AI interaction is logged with complete details: what the customer asked, how the AI responded, which FAQ entries were used, and how many tokens were consumed. Businesses can review conversations, identify areas for improvement, and improve their agent's knowledge base.
To keep costs predictable, we implemented a credit system where 1 credit equals 1 AI message. Businesses can start small and scale as they see value, with complete visibility into usage and costs.
putting it all together
By combining flows, AI agents, and live chat, businesses get the best of both worlds:
- Flows for structured, predictable interactions (appointment booking, menu navigation)
- AI agents for natural language conversations (customer support, product questions)
- Live chat for complex cases requiring human judgment
A typical customer journey might look like this:
- Customer receives a promotional campaign about a new service
- They reply with interest, triggering an automated flow with product options
- They ask an unexpected question ("Is this compatible with X?")
- The AI agent takes over, answering based on its knowledge base
- For pricing negotiation, a human operator joins
- The conversation is tagged and tracked for future marketing
All three systems work together, creating an experience that feels personal at any scale.
the impact
Since launching, blü has transformed how businesses communicate:
- 100+ businesses rely on the platform daily
- 10,000+ monthly active users managing customer conversations
- 1 million+ customers receive messages through blü every day
- Countless hours saved through AI automation and smart workflows
More importantly, businesses tell us they can now provide personalized customer service at a scale that was previously impossible. A small clinic can respond to thousands of inquiries without hiring a large support team. A retail store can nurture leads 24/7 without burning out their staff.
Building blü has been an incredible journey. From a simple WhatsApp broadcasting tool to an AI conversational platform, it represents the evolution of how businesses communicate with customers in Brazil.
The combination of reliable infrastructure, intelligent automation, and human touch has proven to be the right formula for businesses looking to scale their customer communications without losing personalization. And with AI continuing to advance, the potential for even better customer experiences is just beginning.